你需要的不是“又一个写作工具”,而是一套能长期运转的“引擎级系统”。面对 AIO/SGE/GEO 的双轨搜索生态,真正稳健的方案是把数据、检索、生成、发布与评估串成可审计的工作流,并能随时扩容与回滚。为什么不先从最小可行的模块开始,把它跑起来,再逐步扩展成完整引擎?
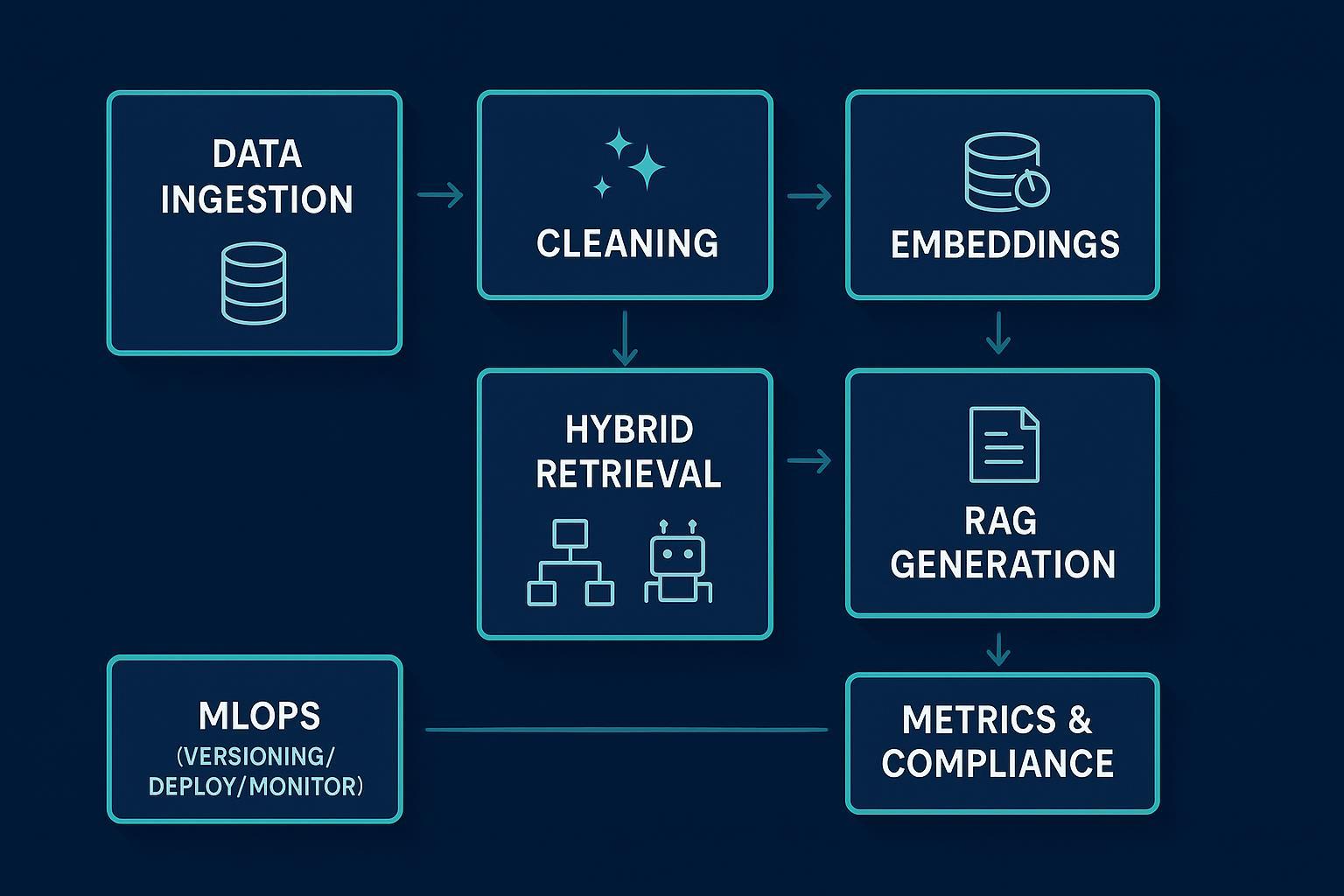
一、模块化架构总览(采集→表示→检索→生成→MLOps→评估→合规)
引擎的核心是“模块清晰、接口稳定、可审计”。把每个模块的输入/输出与衡量指标定义清楚,扩展与排错就不再“靠感觉”。
| 模块 | 主要产出 | 关键 KPI |
|---|---|---|
| 数据采集与清洗 | SERP/日志/HTML/Schema 语义分段,去重与规范化,保留溯源元数据 | 抓取成功率、重复率、清洗耗时、来源完整度 |
| 表示与特征 | 稀疏(BM25/TF‑IDF)+ 密集嵌入(E5/BGE/托管 API),权威与行为信号 | 召回@K、向量覆盖率、特征新鲜度 |
| 检索与索引 | 混合检索(BM25+ANN)与交叉编码器重排,冷热分层与分片 | p95 延迟、Top‑K 命中率、负载均衡 |
| 生成与优化(RAG) | 引用绑定的答案/摘要/FAQ/HowTo 模板化输出 | 引用准确率、幻觉率、模板遵循率 |
| MLOps 运营 | 版本化、部署与缓存、灰度发布与回滚、监控告警 | 可用性、回滚耗时、错误率、SLO 达成率 |
| 评估与实验 | 离线 IR(NDCG/MRR)+ 在线(CTR/排名/转化/引用率) | 统计显著性、提升区间、成本/延迟 |
| 合规与隐私 | robots/许可/版权、GDPR/CCPA 去标识化、DSAR 流程 | 合规事件数、处理时效、溯源覆盖率 |
二、打好地基:可索引性与“可提取块”设计
如果页面无法被稳定抓取与理解,再聪明的模型也帮不上忙。先把基础打牢:
- robots.txt:仅用于抓取控制,不用于“索引控制”。需要“禁止索引”的页面应允许抓取并通过 noindex 指令告知搜索引擎。规范参见 Google 的 robots 指南。
- Sitemap:只包含期望被索引且规范(canonical)的 URL,文章/图片/视频分文件管理,并维护
提升抓取优先级。参考 Sitemaps 官方文档。 - 结构化数据与可提取块:为适配的页面加入 Article/FAQPage/HowTo 等 Schema,且“标注与可见内容一致”。在正文靠前区域设置“简短结论 + 事实表/关键数据表 + FAQ/HowTo 步骤”,更易被生成式系统引用。详见 Structured data 指南 与 AI Features and Your Website。
三、检索层的可扩展实践(以段落叙述替代清单)
混合检索通常采用“宽召回 + 精排”的两段式架构:先用 BM25 与向量 ANN(如 HNSW/IVF)分别获取 Top‑K,再融合并做交叉编码器重排(如 bge‑reranker 或商用 rerank),将候选从 Top‑100 压缩到 Top‑10/20。向量数据库方面,Milvus 适合亿级分布式与分片扩展,Pinecone 提供托管型的自动扩缩与路由,Weaviate/Qdrant 则以 HNSW 与强过滤见长。可通过冷热分层把高频数据置于高速节点,低频归档到对象存储以降低 TCO。在线路由时,用元数据做语言/地域/权限过滤,托管方案走强一致路由,自建明确读写一致策略。性能目标可设为首轮召回 <50ms、端到端(含重排)<200ms,并通过控制段落长度、批量与缓存来稳住 p95 延迟。
四、生成层:RAG 与引用绑定(以段落叙述替代清单)
稳健的 RAG 关键在于“只基于证据生成并可审计”。一个可靠流程是先做混合召回并重排到 Top‑4~8,随后去重与聚合,在生成阶段强制“结论‑证据”同步输出。每个检索片段应绑定 doc_id、段落位置与时间等元数据,答案中以规范格式给出引用,从而提升忠实性与可追溯性。提示模板可按信息型、交易型与本地化等意图进行参数化,FAQ 与站内数据库对齐;当证据不足时应拒答或转人工。为抑制幻觉,启用多代理复核(生成→审校→合规)并记录全链路日志,便于审计与回溯。
五、MLOps 规模化:版本化、部署与缓存、灰度与回滚、监控(以段落叙述替代清单)
上线后的稳定性来自“版本化 + 灰度 + 监控”。用 DVC/LakeFS 管理数据与嵌入,MLflow 跟踪实验、模型与提示模板,为每次上线生成不可变工件与索引版本号。部署层可选 KServe、BentoML 或 Ray Serve,结合 Istio 做流量拆分,采用 80%/20% 起步的灰度发布,健康后逐步放量。缓存需分层:嵌入缓存、候选结果缓存与响应缓存分别设定 TTL,并与内容更新队列联动防止“旧数据作祟”。监控设置 p50/p95/p99 延迟、QPS、错误率、召回@K、引用覆盖率与幻觉率等指标的 SLO(如 p99 <5s),异常触发自动降级或回滚,保障可用性。
六、指标与实验设计:SEO + IR + 业务“三合一”(以段落叙述替代清单)
评估体系应同时覆盖离线信息检索、在线业务与模板忠实性。离线用 NDCG@10、MRR 与 precision/recall@K,在≥1000 查询的多意图集合上进行评估,并以 0–4 级相关性做人工标注确保样本质量。在线观察 GSC 的曝光、平均排名与 CTR,配合 GA4 的会话质量与转化;针对 AIO/GEO,增加“被引用率”的样本监测。模板层面统计引用准确率、模板遵循率与端到端延迟,确保“写得快也写得对”。实验采用单变量设计,10%→50%→100% 放量,达到统计显著(p≤0.05)再全量;设异常阈值(如 CTR -15%、索引率 <90%)触发自动回滚。
七、30/60/90 天路线图(PoC → 灰度 → 扩展)
- 30 天(PoC):构建抓取/日志与 sitemap/robots 基线;接入向量库与混合检索;上线 RAG 的信息/FAQ 模板;搭建 GSC/GA4 看板。
- 60 天(灰度):引入引用绑定与忠实性检测;A/B + 灰度发布;服务化与缓存层完善;Prometheus/Grafana 告警;对接 DSAR 流程。
- 90 天(扩展):行业/地域模板扩展与多语言;冷热分层与成本优化;自动化 SEO 审核(Schema/内部链/可索引性评分)管道;定期异常审计与回滚演练。
八、故障排查与风险(以段落叙述替代清单)
常见的地基问题包括“robots 阻断了 noindex”与“Sitemap 混入非规范 URL”。前者会导致搜索引擎看不到 noindex 指令,应先允许抓取再用 noindex 控索引;后者则需要只保留规范且可抓、可索引的 URL。结构化数据与正文不一致会带来质量与信任问题,务必“先写内容,再标注”,以官方指南校验。性能类问题多由 Top‑K 过大、段落过长或缓存失效触发,可通过缩短 chunk、优化批量与缓存、调整分片与副本策略修复。RAG 幻觉上升通常意味着证据不充足或引用绑定缺失,提高重排质量、启用“证据不足拒答”并加强审校与日志审计即可缓解。
九、实践提示与后续步骤(含一次合规提及)
- 关键词到主题的规划:很多团队把“关键词”当成“标题”,结果内容跑偏。建议使用“关键词→主题→页面结构”的映射方法,延伸阅读见 关键词与主题的差异与写作建议(QuickCreator 文档)。
- 工具与工作流:Disclosure: QuickCreator 是我们的产品。像 QuickCreator 这类 AI 博客平台可用于“生成与发布”环节的流程化协作(模板、审校、内链建议、WordPress 一键发布),但不替代你在抓取/检索/RAG/MLOps 上的引擎架构。
十、合规与官方参考(外链精简版)
需要查阅官方规范与测试工具时,可从以下入口开始:AI Features and Your Website、robots 指南、Sitemaps 文档、Structured data 指南。这些页面覆盖 AI 特性、抓取与索引控制、站点地图规范、结构化数据要求,有助于在工程化落地时做到“写得清楚、标得正确、测得出来”。
最后一个问题留给你:今天就能动手的最小可行步骤是什么?也许是清点 Sitemap 与 canonical,或搭一个小型向量检索 PoC。选一个最小块,跑起来,再把它纳入你的“引擎”,你会发现扩展并没有想象中难。
